
GenAI Just Got a Little Less Opaque
Yesterday, a breakthrough in AI research brought us closer to understanding the inner workings of large language models (LLMs). For the first time, a team of researchers successfully interpreted the complex processes behind these models, shedding light on the previously opaque mechanisms that govern their behavior.
 Unlocking the Secrets of AI
Unlocking the Secrets of AI
The technique, known as dictionary learning, leverages a sparse encoder to isolate specific concepts within the model. This allowed the researchers to extract millions of features, including specific entities like the Golden Gate Bridge and more abstract ideas such as gender bias. They were then able to map the proximity of related concepts, such as “inner conflict” and “Catch-22.” Most importantly, they were able to activate and suppress features to change model behavior.
“The computation required by our current approach would vastly exceed the compute used to train the model in the first place.” - Anthropic
While this breakthrough is significant, it’s essential to acknowledge that we’ve only scratched the surface. Interpreting the entire model would be too costly, and we still have a long way to go before achieving full explainability.
 The Future of AI Depends on Explainability
The Future of AI Depends on Explainability
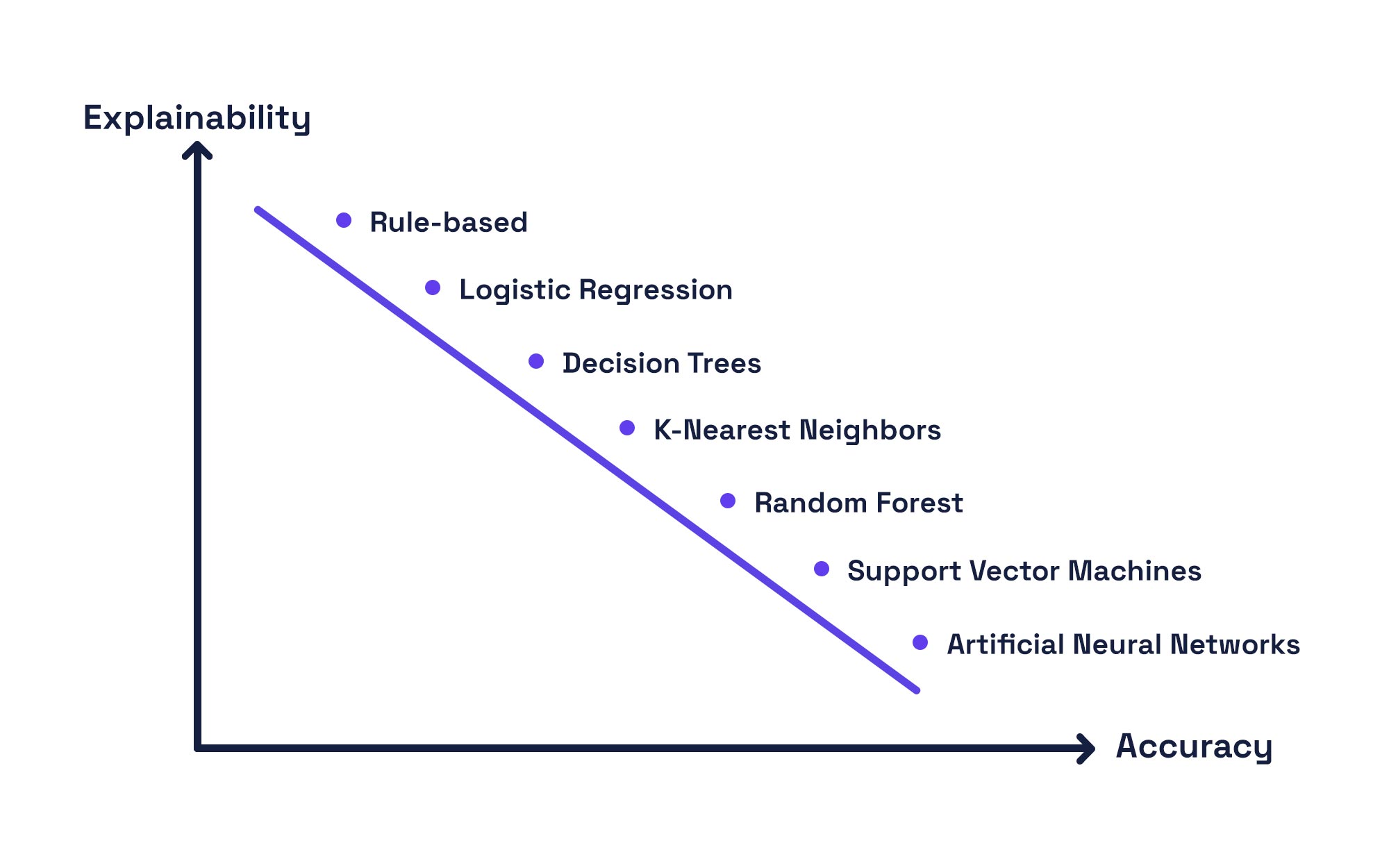
There is no alignment without explainability. Over the last six months, I have been conducting research on AI alignment with Brian Hopkins and Enza Iannopollo. We have found that the limitations of current AI approaches make misalignment inevitable. AI misalignment could create catastrophic consequences for businesses and society. Full model explainability would enable us to tweak the very DNA of LLMs, bringing them into alignment with business and societal needs.
Opacity precludes insight. The world is enamored of LLMs’ ability to produce novel text, audio, images, video, and code. But we are currently ignorant of the patterns that the models learned about humanity to produce those outputs. The training of LLMs could be considered the largest sociological study of humanity in the history of the world. Unfortunately, without explainability, we have no way of interpreting the study’s results.
Transparency is AI’s most powerful trust lever. The opacity of AI has created a significant trust gap that only transparency can fully bridge. Until we can explain exactly how a prompt leads to a response, there will be skepticism among consumers, regulators, and business stakeholders alike.
 The Key to Unlocking Trust in AI
The Key to Unlocking Trust in AI
The explainability of predictive AI was a vexing issue a decade ago. Now, it is largely solved, thanks to the hard work of diligent researchers responding to industry demands. It’s time to make similar demands. The success of AI depends on it.














{kind=link}