
Reasoning Abilities of Large Language Models: A Deeper Dive into Geometric Understanding
===============
Large language models (LLMs) have left us all in awe with their remarkable performance across various tasks. However, it’s intriguing to explore the key elements driving these improvements. While increasing model size and expanding context length have proven effective, they only represent a fraction of potential improvement avenues, often leading to increased computational costs and inference latency in real-world applications.
To gain a comprehensive end-to-end perspective, researchers from Tenyx have taken a geometric approach to analyze the transformer layers in LLMs, focusing on key properties correlated with their expressive power. Their study reveals two critical factors: the density of token interactions in the multi-head attention (MHA) module, which reflects the complexity of function representation achievable by the subsequent multi-layer perceptron (MLP), and the relationship between increased model size and context length with higher attention density and improved reasoning.
 A representation of LLMs’ geometric structure, correlating with their reasoning capabilities.
A representation of LLMs’ geometric structure, correlating with their reasoning capabilities.
By exploring the intrinsic dimension of the self-attention block and analyzing the graph density of each attention head, the study aims to capture the expressive power of LLMs and deepen our understanding of their behavior, potentially opening new avenues for advancing LLM capabilities.
Experiments using the GSM8K-Zero dataset reveal a correlation between expressive power and reasoning capabilities, suggesting that enhancing input complexity to MLP blocks can improve LLMs’ reasoning performance. Moreover, the study demonstrates a strong correlation between the intrinsic dimension (ID) of the last layers and response correctness, regardless of model size.
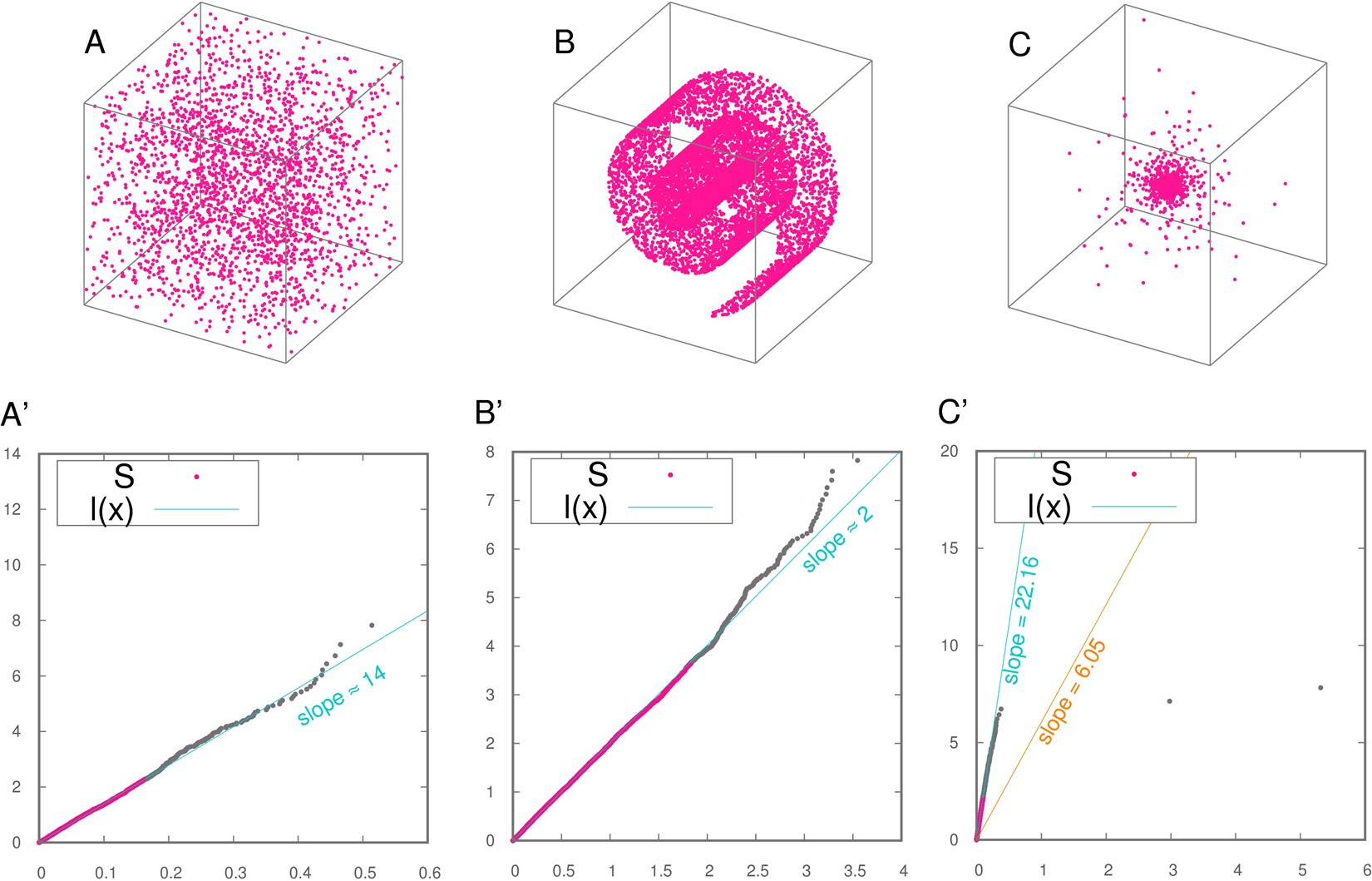 A visualization of the intrinsic dimension of LLMs, correlating with their reasoning capabilities.
A visualization of the intrinsic dimension of LLMs, correlating with their reasoning capabilities.
The findings indicate that increasing context in prompts can raise the ID, particularly when the context is relevant to the question, leading to more piece-wise affine maps in the MLP and resulting in more adaptive transformations for each token. From an approximation standpoint, finer partitioning around tokens reduces overall prediction error.
The study’s results demonstrate that higher ID changes correlate with increased probability of correct responses. However, the relationship between these geometric insights and the generalization capabilities of LLMs remains an unexplored area, warranting further investigation to understand the models’ robustness and adaptability across various contexts.
 A representation of LLMs’ generalization capabilities, awaiting further exploration.
A representation of LLMs’ generalization capabilities, awaiting further exploration.
As we continue to push the boundaries of LLMs, it’s essential to explore new avenues for advancing their capabilities. By delving deeper into the geometric understanding of these models, we can unlock their full potential and pave the way for more significant breakthroughs in AI research.














{kind=link}