
The Next Big Trends in Large Language Model (LLM) Research
Large Language Models (LLMs) are rapidly developing with advances in both the models’ capabilities and applications across multiple disciplines. In recent times, various trends in LLM research have emerged, including the development of multimodal, open-source, domain-specific, and smaller LLMs, as well as LLM agents and non-transformer LLMs.
Multimodal LLMs
With the ability to integrate several types of input, including text, photos, and videos, multimodal LLMs constitute a major advancement in artificial intelligence. These models are extremely adaptable for various applications since they can comprehend and generate material across multiple modalities. Multimodal LLMs are built to perform more complex and nuanced tasks, such as answering questions about images or producing in-depth video material based on textual descriptions, by utilizing large-scale training on a variety of datasets.
Multimodal LLMs are revolutionizing AI research
Examples of multimodal LLMs include OpenAI’s Sora, which has made significant progress in AI, especially in text-to-video generation. This model uses a variety of video and image data, such as different durations, resolutions, and aspect ratios, to train text-conditional diffusion models. Sora generates high-fidelity films for up to one minute by processing spacetime patches of video and image latent codes using an advanced transformer architecture. Another example is Google’s Gemini family of multimodal models, which is highly adept at comprehending and producing text, audio, video, and image-based material.
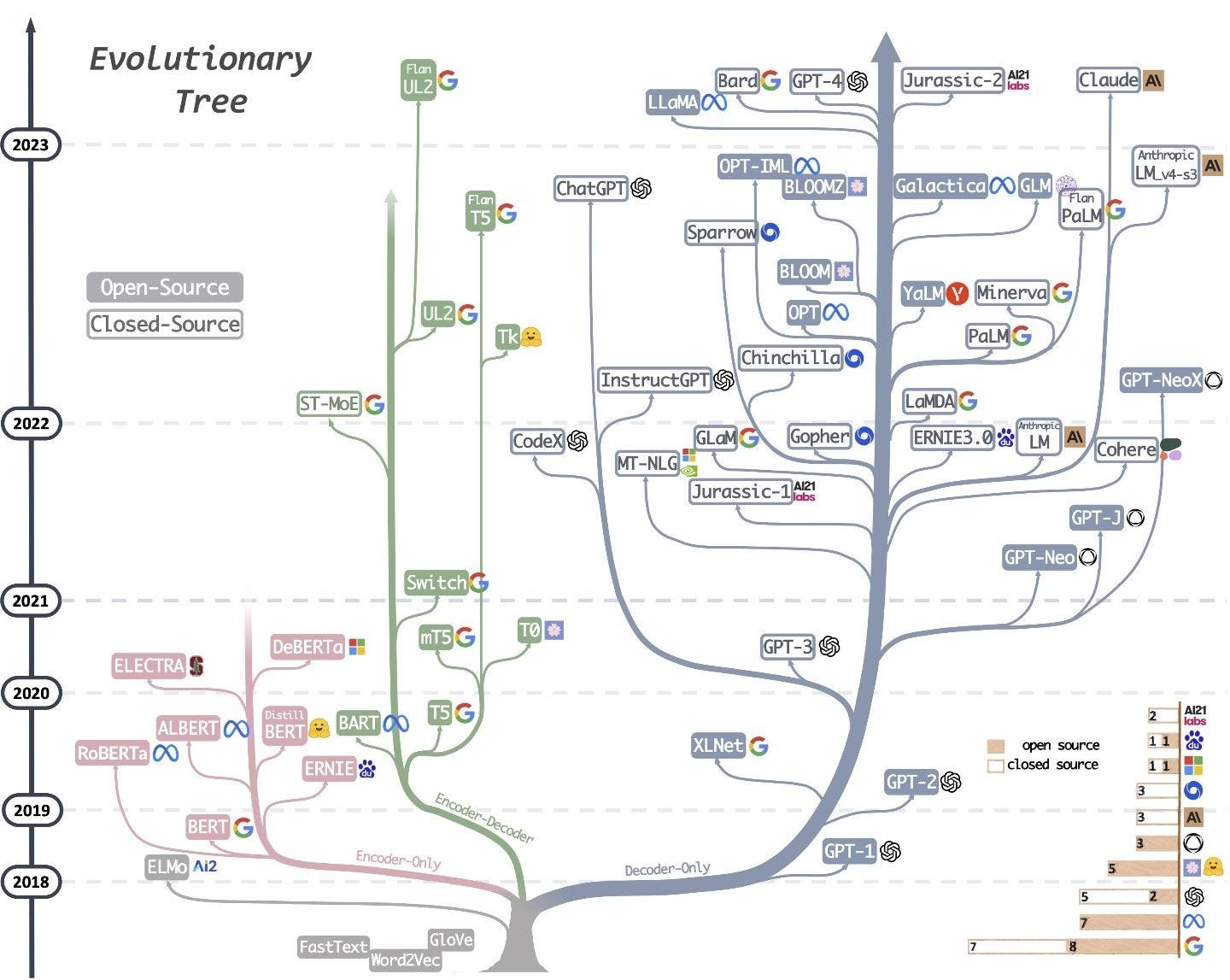
Open-Source LLMs
Large Language Models that are available as open-source software have democratized AI research by enabling the world community to access sophisticated models and the training processes behind them. With this, transparent access is provided to model designs, training data, and code implementations. In addition to fostering cooperation and accelerating discovery, this transparency guarantees reproducibility in AI research.
 Open-source LLMs are democratizing AI research
Open-source LLMs are democratizing AI research
Examples of open-source LLMs include LLM360, which seeks to transform the field of LLMs by promoting total transparency in model creation. This project exposes training data, code, and intermediate results along with final weights for models such as AMBER and CRYSTALCODER. Another example is LLaMA, which is a substantial improvement in open-source LLMs. LLaMA-13B, which was trained only on publicly accessible datasets, has outperformed much bigger proprietary models across a range of benchmarks.
Domain-Specific LLMs
Domain-specific LLMs are designed to perform better in specialized tasks by utilizing domain-specific data and fine-tuning strategies, such as programming and biomedicine. These models not only enhance work performance but also show how AI may be used to solve complicated problems in a variety of professional fields.
Domain-specific LLMs are solving real-world problems
Examples of domain-specific LLMs include BioGPT, which improves activities like biomedical information extraction and text synthesis. In a number of biomedical natural language processing tasks, it performs better than earlier models, proving its ability to comprehend and produce biomedical text efficiently. Another example is StarCoder, which concentrates on understanding programming languages and generating code. It is highly proficient in software development activities because of its thorough training on big code datasets.
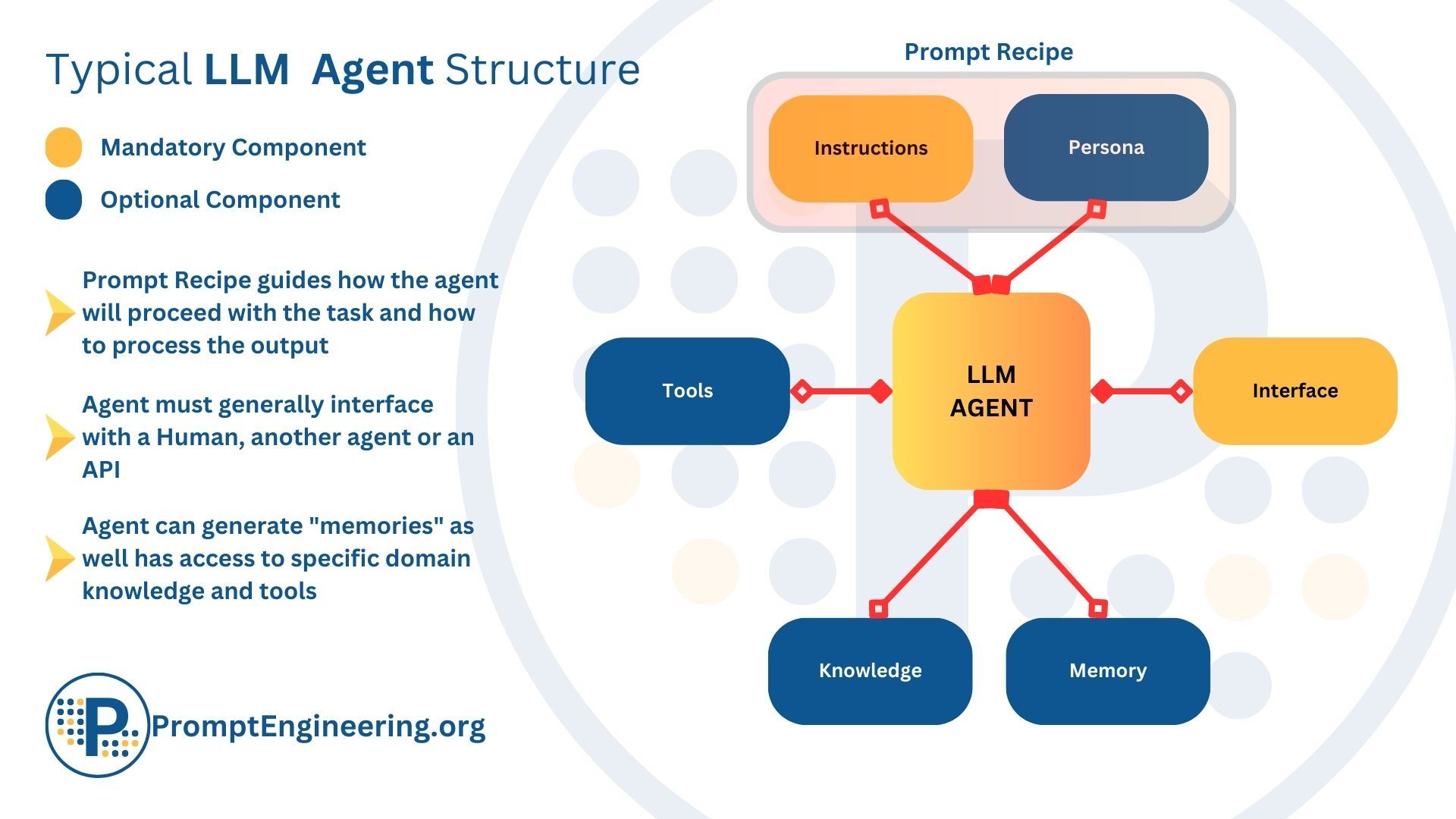
LLM Agents
Large Language Models power LLM Agents, which are sophisticated AI systems. They use their strong language skills to flourish in jobs like content development and customer service. These agents process natural language queries and carry out tasks in various fields, such as making suggestions or producing artistic works. LLM Agents simplify interactions when they are integrated into applications like chatbots and virtual assistants.
 LLM agents are revolutionizing customer service
LLM agents are revolutionizing customer service
Examples of LLM agents include ChemCrow, which unifies 18 specialized tools into a single platform, transforming computational chemistry. This LLM-based agent can independently synthesize insect repellents, organocatalysts, and new chromophores. It also excels in chemical synthesis, drug discovery, and materials design. Another example is ToolLLM, which improves on open-source LLMs by emphasizing the usability of tools.
Smaller LLMs (Including Quantized LLMs)
Smaller LLMs, such as quantized versions, are appropriate for resource-constrained device deployment since they serve applications that demand less precision or fewer parameters. These models facilitate deployment in edge computing, mobile devices, and other scenarios requiring effective AI solutions by enabling broader accessibility and application of large-scale language processing capabilities in environments with limited computational resources.
Smaller LLMs are enabling AI on edge devices
Examples of smaller LLMs include BitNet, which is a 1-bit LLM that was first introduced in research as BitNet b1.58. With ternary weights {-1, 0, 1} for each parameter, this model greatly improves cost-efficiency while performing in a manner that is comparable to full-precision models in terms of perplexity and task performance. Another example is Gemma 1B, which is a modern, lightweight open variant based on the same technology as the Gemini series.
Non-Transformer LLMs
Language models known as Non-Transformer LLMs depart from the conventional transformer architecture by frequently introducing components such as Recurrent Neural Networks (RNNs). Some of the main drawbacks and issues with transformers, like their expensive computing costs and ineffective handling of sequential data, are addressed by these approaches. Non-transformer LLMs provide unique approaches to improve model performance and efficiency by investigating alternative designs.
 Non-transformer LLMs are offering new approaches to AI
Non-transformer LLMs are offering new approaches to AI
Examples of non-transformer LLMs include Mamba, which addresses the computational inefficiencies of the Transformer architecture, especially with extended sequences. In contrast to conventional models, Mamba is not constrained by subquadratic-time architectures, which have trouble with content-based reasoning. Another example is RWKV, which creatively blends the advantages of Transformers and Recurrent Neural Networks (RNNs).














{kind=link}