 Photo by
Photo by The Future of Language Models: Attention-Free and State-of-the-Art
The RWKV neural architecture is revolutionizing the field of natural language processing. By ditching the traditional attention mechanism, RWKV models are able to process sequences more efficiently than their transformer-based counterparts. But what does this mean for the future of language models, and how can we harness their power for multilingual tasks?
In my previous article, I delved into the world of RWKV and explored its potential applications. Today, I want to take a closer look at what makes RWKV so special, and why it’s poised to change the game for language models.
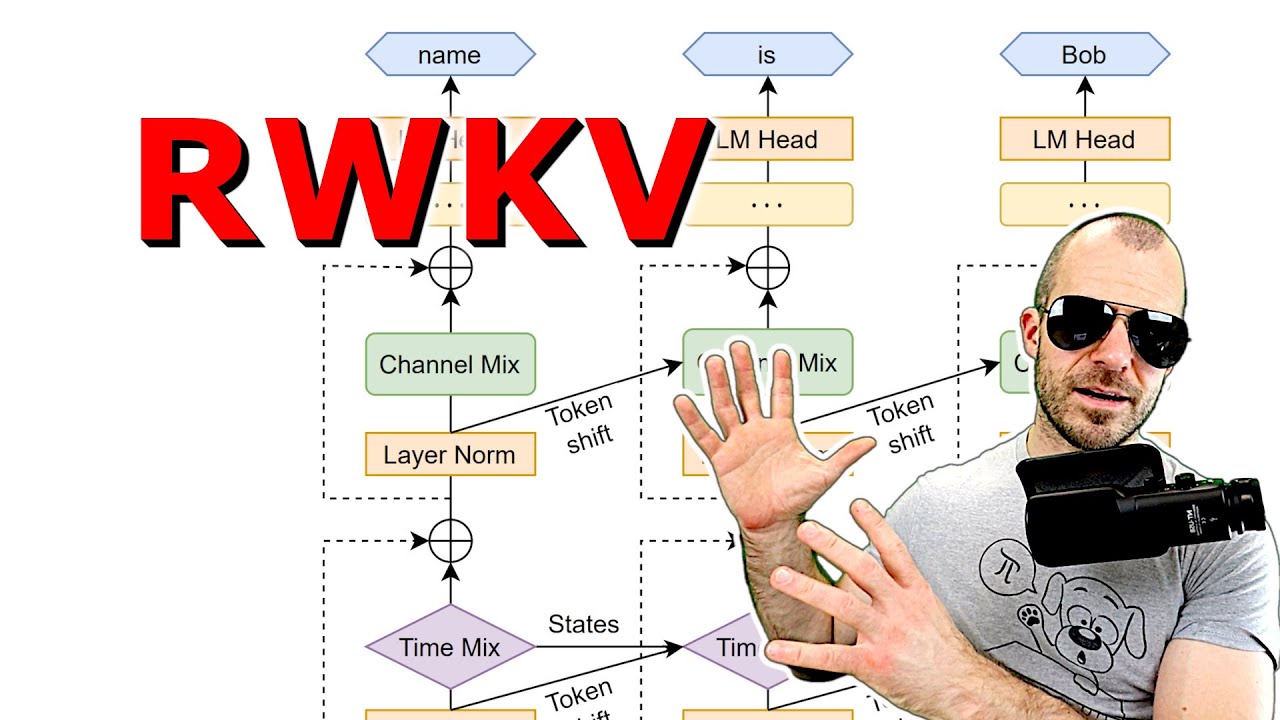 RWKV’s attention-free architecture makes it more efficient than traditional transformer models.
RWKV’s attention-free architecture makes it more efficient than traditional transformer models.
One of the key advantages of RWKV is its ability to process sequences of arbitrary length without the need for attention. This makes it particularly well-suited for multilingual tasks, where sequences can be long and complex. But how does it achieve this?
The answer lies in RWKV’s unique architecture. By using a combination of convolutional and recurrent layers, RWKV is able to capture long-range dependencies in sequences without the need for attention. This makes it faster and more efficient than traditional transformer models, which rely on attention to process sequences.
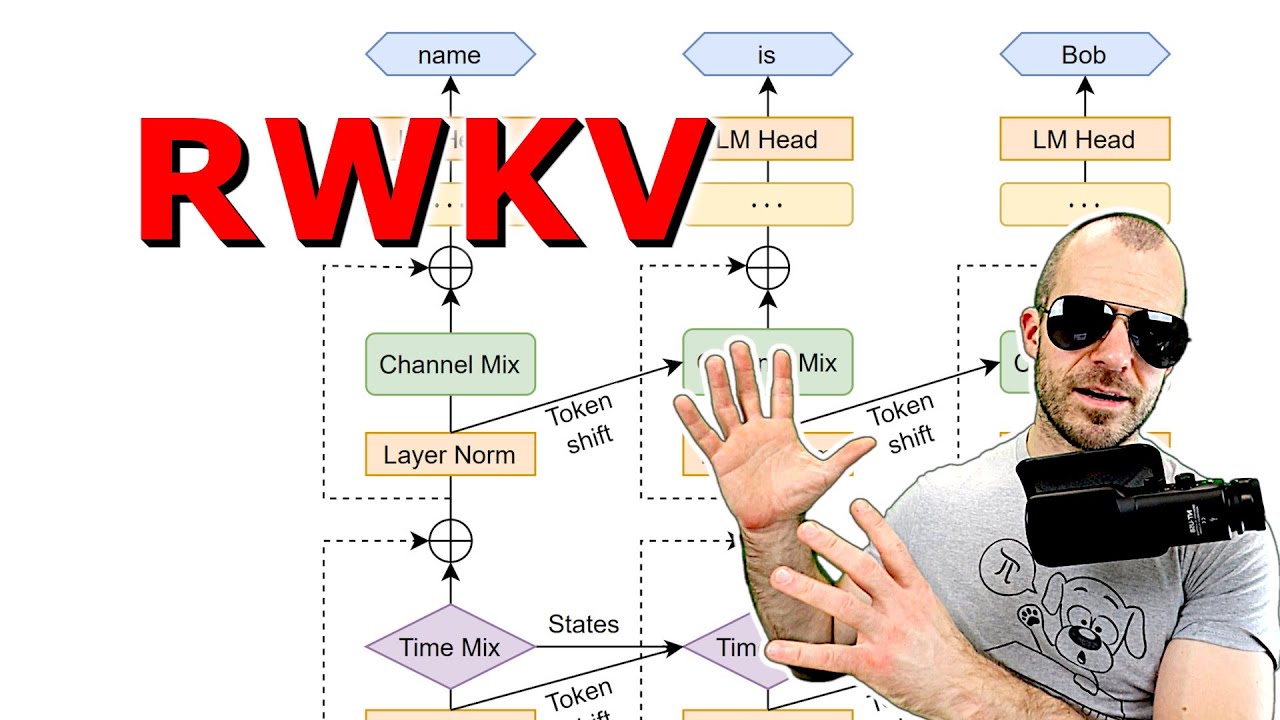 RWKV’s attention-free architecture makes it faster and more efficient than traditional transformer models.
RWKV’s attention-free architecture makes it faster and more efficient than traditional transformer models.
So what does this mean for the future of language models? In my opinion, RWKV is poised to revolutionize the field of natural language processing. Its ability to process sequences efficiently and accurately makes it an ideal choice for a wide range of applications, from machine translation to text summarization.
As we move forward, I believe we’ll see RWKV models being used in a variety of exciting new applications. From chatbots and virtual assistants to language translation and text analysis, the possibilities are endless.
RWKV has the potential to revolutionize a wide range of applications, from chatbots to language translation.
In conclusion, RWKV is a game-changer for the field of natural language processing. Its attention-free architecture makes it faster and more efficient than traditional transformer models, and its potential applications are vast. As we move forward, I’m excited to see how RWKV will continue to shape the future of language models.
“The future of language models is attention-free, and it’s going to change everything.”











