
Supercharging Large Language Models with Multi-token Prediction
Large language models (LLMs) have taken the world by storm with their remarkable ability to understand and generate human-like text. However, despite their impressive capabilities, the standard method of training these models, known as “next-token prediction,” has some inherent limitations.
In next-token prediction, the model is trained to predict the next word in a sequence given the preceding words. While this approach has proven successful, it can lead to models that struggle with long-range dependencies and complex reasoning tasks. Moreover, the mismatch between the teacher-forcing training regime and the autoregressive generation process during inference can result in suboptimal performance.
A recent research paper by Gloeckle et al. (2024) from Meta AI introduces a novel training paradigm called “multi-token prediction” that aims to address these limitations and supercharge large language models. In this article, we’ll dive deep into the core concepts, technical details, and potential implications of this groundbreaking research.
The Limitations of Next-Token Prediction
The next-token prediction approach has been the cornerstone of large language model training. However, this method has some significant drawbacks. For instance, it can lead to models that struggle with long-range dependencies, making it challenging to capture complex contextual relationships in text. Additionally, the mismatch between the training and inference processes can result in suboptimal performance.
 Caption: A visual representation of a large language model
Caption: A visual representation of a large language model
The Emergence of Multi-Token Prediction
The multi-token prediction approach, as proposed by Gloeckle et al. (2024), offers a promising solution to the limitations of next-token prediction. This novel training paradigm involves predicting multiple tokens simultaneously, rather than just the next token in a sequence. This approach has the potential to improve the performance of large language models in various natural language processing tasks.
 Caption: Researchers working on AI models
Caption: Researchers working on AI models
Technical Details of Multi-Token Prediction
The multi-token prediction approach involves several key components. Firstly, the model is trained on a dataset of input sequences, where each sequence is paired with a target output sequence. The model is then trained to predict multiple tokens simultaneously, rather than just the next token in a sequence. This approach allows the model to capture complex contextual relationships in text more effectively.
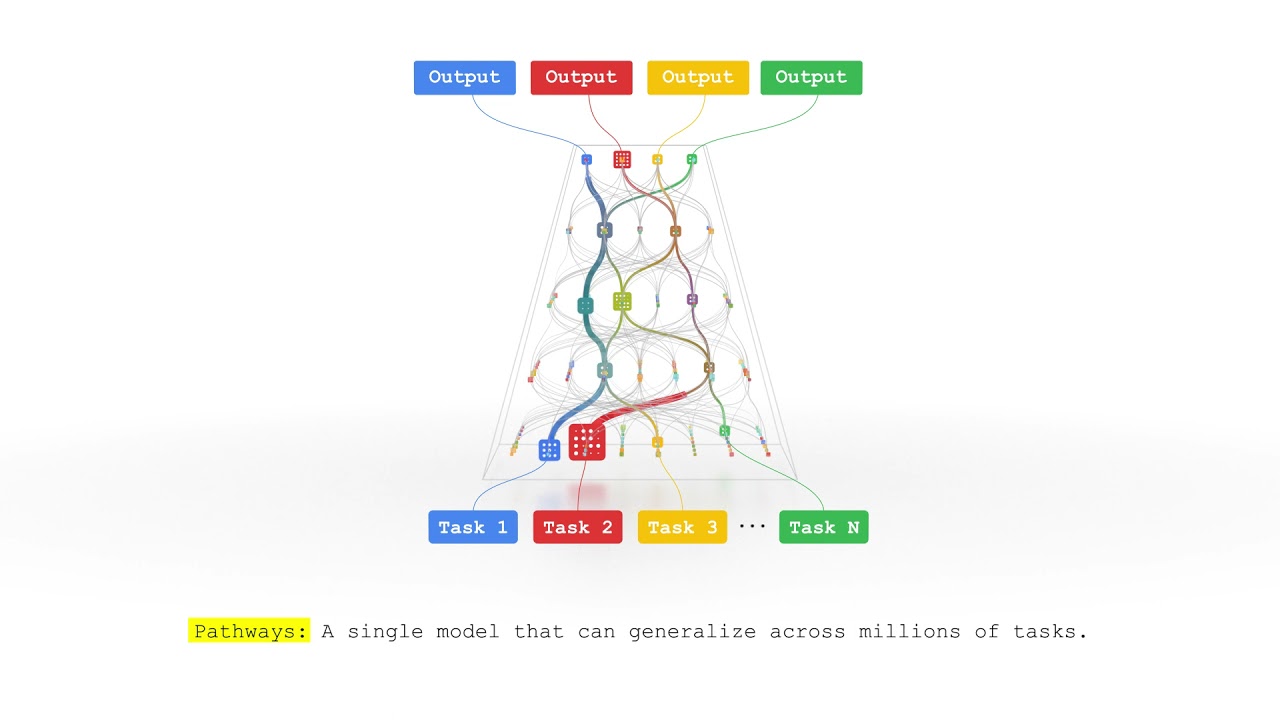 Caption: A high-level overview of the multi-token prediction model architecture
Caption: A high-level overview of the multi-token prediction model architecture
Potential Implications of Multi-Token Prediction
The multi-token prediction approach has significant implications for the development of large language models. With the ability to capture complex contextual relationships in text, these models can be fine-tuned for a wide range of natural language processing tasks, such as text classification, sentiment analysis, and machine translation.
 Caption: Potential applications of multi-token prediction in AI
Caption: Potential applications of multi-token prediction in AI
In conclusion, the multi-token prediction approach has the potential to revolutionize the field of large language models. By addressing the limitations of next-token prediction, this novel training paradigm can lead to more accurate and efficient models that can be applied to a wide range of natural language processing tasks.














{kind=link}