 Photo by
Photo by Optimizing LLM Apps: 5 Techniques to Reduce Costs and Latency
The widespread adoption of Large Language Models (LLMs) has revolutionized the way we approach natural language processing tasks. However, as LLMs continue to grow in size and complexity, they also bring about significant challenges, particularly when it comes to costs and latency. In this article, we’ll explore five techniques to optimize token usage, reducing costs and latency without sacrificing accuracy.
The Cost Conundrum
High costs and latency are significant obstacles when launching LLM Apps in production. Both are strongly related to prompt size, making it essential to find ways to optimize token usage without compromising on accuracy. This is particularly crucial for businesses and organizations that rely heavily on LLMs for their operations.
Technique 1: Prompt Engineering
One effective way to reduce costs and latency is through prompt engineering. This involves designing and optimizing prompts to minimize token usage while maintaining accuracy. By crafting well-designed prompts, developers can significantly reduce the computational resources required, leading to lower costs and faster processing times.
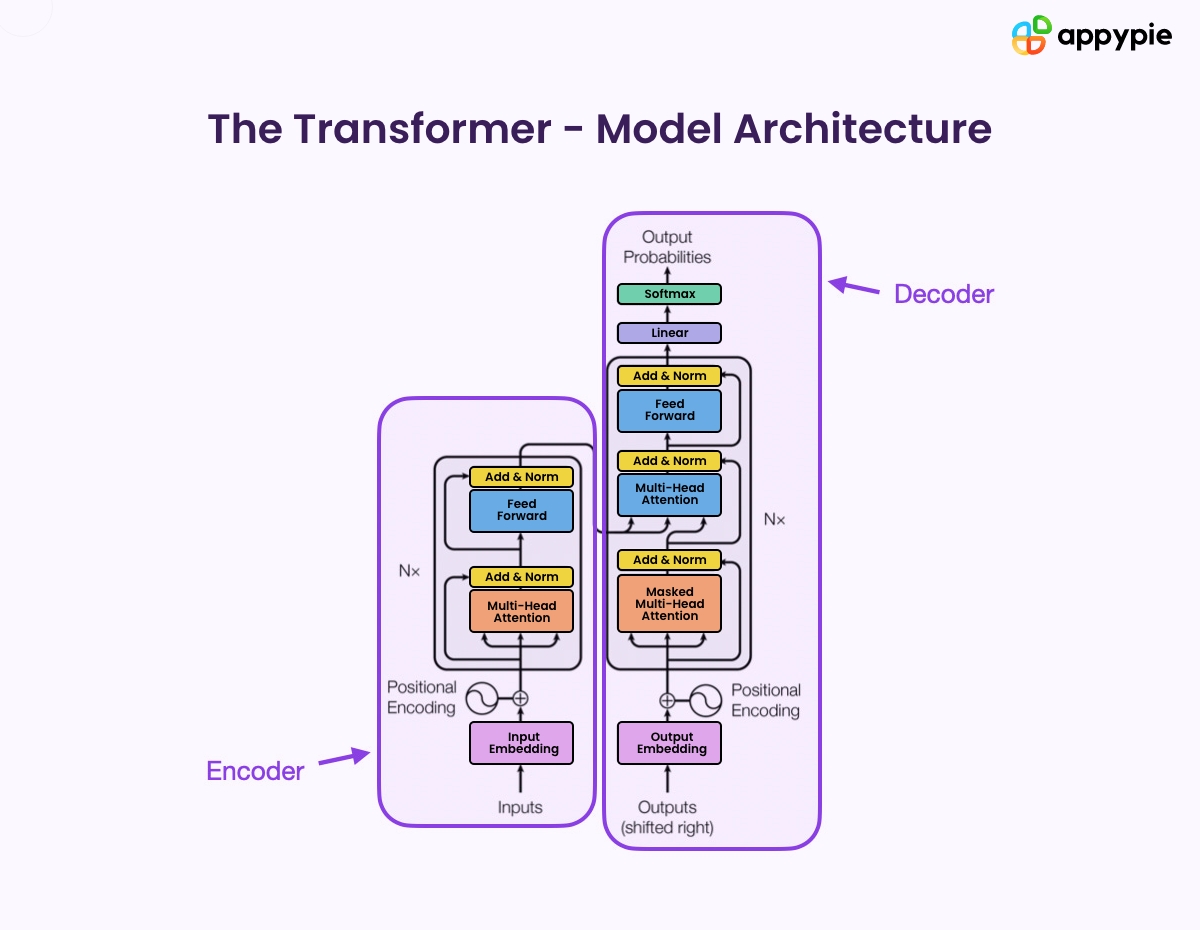 Optimizing LLM Architecture for Efficiency
Optimizing LLM Architecture for Efficiency
Technique 2: Token Pruning
Token pruning is another technique that can help reduce costs and latency. This involves removing unnecessary tokens from the input prompt, reducing the overall computational load on the LLM. By pruning tokens, developers can minimize the amount of processing required, leading to faster processing times and lower costs.
Technique 3: Model Pruning
Model pruning is a technique that involves removing redundant or unnecessary components from the LLM architecture. By pruning the model, developers can reduce the computational resources required, leading to faster processing times and lower costs.
Technique 4: Knowledge Distillation
Knowledge distillation is a technique that involves transferring knowledge from a larger, more complex LLM to a smaller, more efficient model. This approach can help reduce costs and latency by minimizing the computational resources required.
Technique 5: Quantization
Quantization is a technique that involves reducing the precision of the LLM’s weights and activations. By reducing the precision, developers can minimize the computational resources required, leading to faster processing times and lower costs.
Conclusion
Optimizing LLM Apps is crucial for reducing costs and latency. By employing techniques such as prompt engineering, token pruning, model pruning, knowledge distillation, and quantization, developers can minimize the computational resources required, leading to faster processing times and lower costs. As the use of LLMs continues to grow, it’s essential to prioritize optimization techniques to ensure efficient and cost-effective operations.
 The Future of Efficient LLM Architecture
The Future of Efficient LLM Architecture









