
The Future of LLM Inference: Efficient KV Cache Compression with PyramidInfer
Large Language Models (LLMs) have revolutionized the field of natural language processing, but their scalability is limited by high GPU memory usage during inference. The KV cache, a critical component of LLMs, consumes a significant amount of memory, restricting the throughput of LLM inference on GPUs. To address this challenge, researchers have developed PyramidInfer, a novel approach that compresses the KV cache, enabling efficient LLM inference.
GPU memory usage during LLM inference
Existing methods reduce memory by compressing the KV cache but overlook inter-layer dependencies and pre-computation memory demands. PyramidInfer, on the other hand, retains only crucial context keys and values layer-by-layer, significantly reducing GPU memory usage. Inspired by recent tokens’ consistency in attention weights, this approach has been shown to improve throughput by 2.2x and reduce KV cache memory by over 54% compared to existing methods.
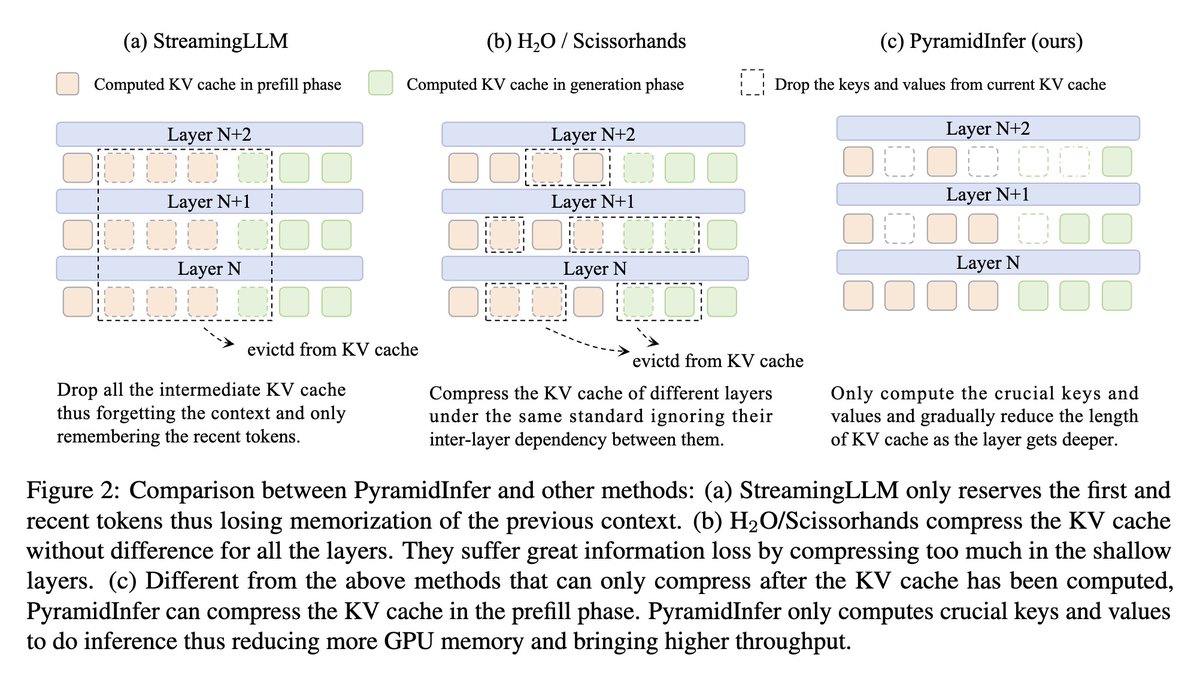
The importance of efficient strategies for handling the growing demand for chatbot queries cannot be overstated. One approach is increasing GPU memory through pipeline parallelism and KV cache offload, utilizing multiple GPUs or RAM. For limited GPU memory, reducing the KV cache is another option. Techniques like FlashAttention 2 and PagedAttention minimize memory waste by optimizing CUDA operations. Methods such as StreamingLLM, H2O, and Scissorhands compress the KV cache by focusing on recent context or attention mechanisms but overlook layer differences and prefill phase compression. PyramidInfer addresses these gaps by considering layer-specific compression in both phases.
 PyramidInfer’s layer-specific compression approach
PyramidInfer’s layer-specific compression approach
The verification of the Inference Context Redundancy (ICR) and Recent Attention Consistency (RAC) hypotheses inspired the design of PyramidInfer. ICR posits that many context keys and values are redundant during inference and are only necessary in training to predict the next token. Experiments with a 40-layer LLaMA 2-13B model revealed that deeper layers have higher redundancy, allowing for significant KV cache reduction without affecting output quality. RAC confirms that certain keys and values are consistently attended by recent tokens, enabling the selection of pivotal contexts (PVCs) for efficient inference.
PyramidInfer’s performance was evaluated across various tasks and models, demonstrating significant reductions in GPU memory usage and increased throughput while maintaining generation quality. The evaluation included language modeling on wikitext-v2, LLM benchmarks like MMLU and BBH, mathematical reasoning with GSM8K, coding via HumanEval, conversation handling with MT-Bench, and long text summarization using LEval. PyramidInfer was tested on models such as LLaMA 2, LLaMA 2-Chat, Vicuna 1.5-16k, and CodeLLaMA across different sizes.
 PyramidInfer’s performance evaluation across various tasks and models
PyramidInfer’s performance evaluation across various tasks and models
In conclusion, PyramidInfer introduces an efficient method to compress the KV cache during both prefill and generation phases, inspired by ICR and RAC. This approach significantly reduces GPU memory usage without compromising model performance, making it ideal for deploying large language models in resource-constrained environments. Despite its effectiveness, PyramidInfer requires additional computation, limiting speedup with small batch sizes. As the first to compress the KV cache in the prefill phase, PyramidInfer is yet to be a lossless method, indicating potential for future improvements in this area.














{kind=link}