
Revolutionizing Large Language Models: The Power of Branch-Train-Mix
As I delve into the world of artificial intelligence, I am constantly amazed by the relentless pursuit of innovation in this field. The development of Large Language Models (LLMs) has been a cornerstone of various applications, ranging from natural language processing to code generation. However, the traditional training methods have often resulted in a steep trade-off between breadth and depth of knowledge. The challenge of efficiently scaling their abilities has become increasingly pronounced.
 Illustration of a Large Language Model
Illustration of a Large Language Model
Recent methodologies have addressed this issue by segmenting the training process, focusing on developing domain-specific expertise within the models. However, these segmented training processes have faced their own challenges, particularly in balancing specialized training with the maintenance of a model’s general capabilities.
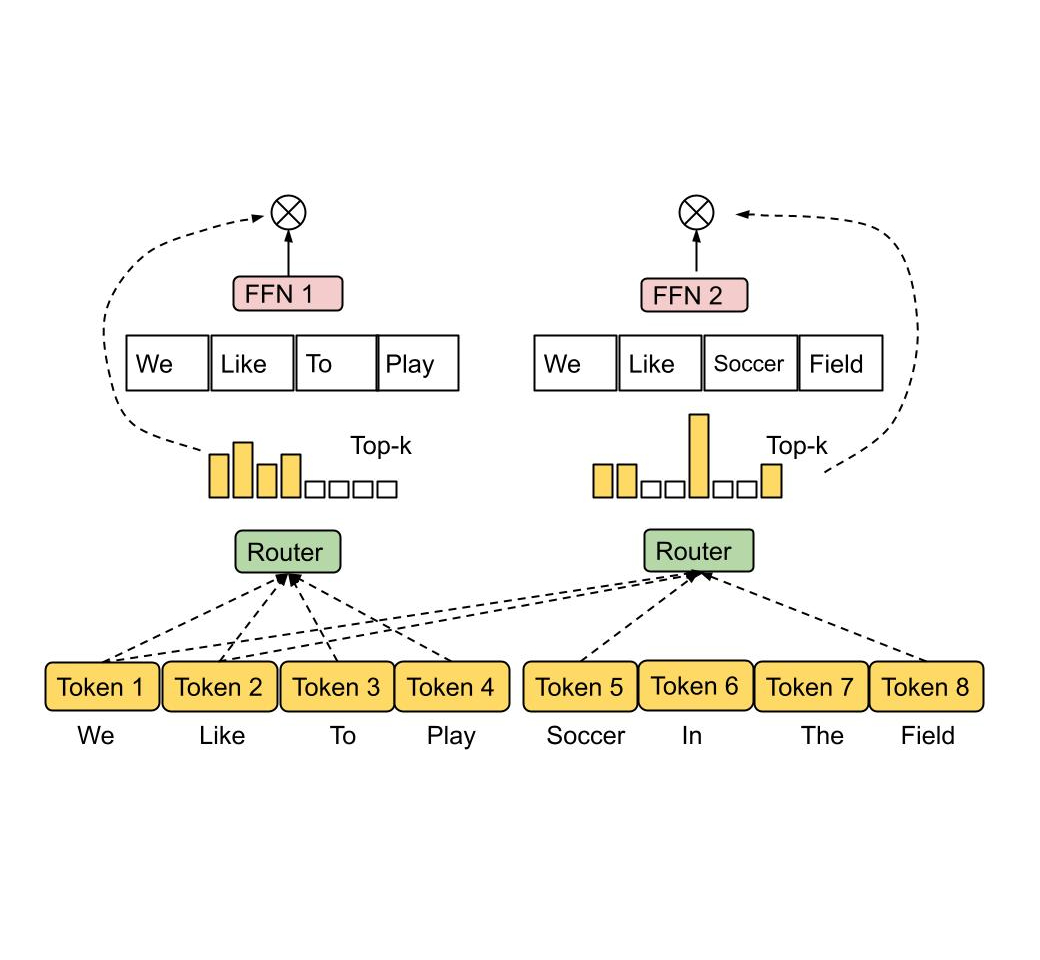 Mixture of Experts (MoE) model
Mixture of Experts (MoE) model
Researchers from FAIR at Meta have introduced Branch-Train-Mix (BTX), a pioneering strategy that combines parallel training with the Mixture-of-Experts (MoE) model. BTX distinguishes itself by initiating parallel training for domain-specific experts, followed by a strategic amalgamation of these experts into a unified MoE framework to enhance the model’s overall efficacy and versatility.
 Branch-Train-Mix (BTX) methodology
Branch-Train-Mix (BTX) methodology
The efficacy of the BTX model was tested across a broad spectrum of benchmarks, showcasing its ability to retain and enhance performance in specialized domains. This was achieved with impressive efficiency, minimizing the additional computational demands typically associated with such enhancements.
 Efficiency of the BTX model
Efficiency of the BTX model
This research encapsulates a significant stride towards optimizing the training of LLMs, offering a glimpse into the future of artificial intelligence development. The BTX method represents a nuanced approach to enhancing the depth and breadth of LLM capabilities, marking a pivotal shift towards more efficient, scalable, and adaptable training paradigms.
 The future of artificial intelligence development
The future of artificial intelligence development
In conclusion, the BTX methodology has the potential to revolutionize the field of LLMs, offering a scalable and adaptable approach to training. As we continue to push the boundaries of AI development, it is essential to prioritize efficiency, versatility, and innovation.














{kind=link}