
Apple’s Innovative Multimodal AI Approach to Speech Detection
In a groundbreaking move, Apple researchers have introduced a revolutionary multimodal system for device-directed speech detection, leveraging the power of large language models (LLMs). This cutting-edge approach combines acoustic data, linguistic cues, and outputs from automatic speech recognition (ASR) systems to enhance the accuracy and efficiency of speech identification.
The core challenge addressed by Apple’s research team is the precise identification of spoken commands intended for devices amidst varying levels of background noise and speech. Traditional methods often struggle in noisy environments or when faced with ambiguous speech scenarios. Apple’s solution eliminates the need for trigger phrases, enabling users to engage with their devices more naturally and spontaneously.
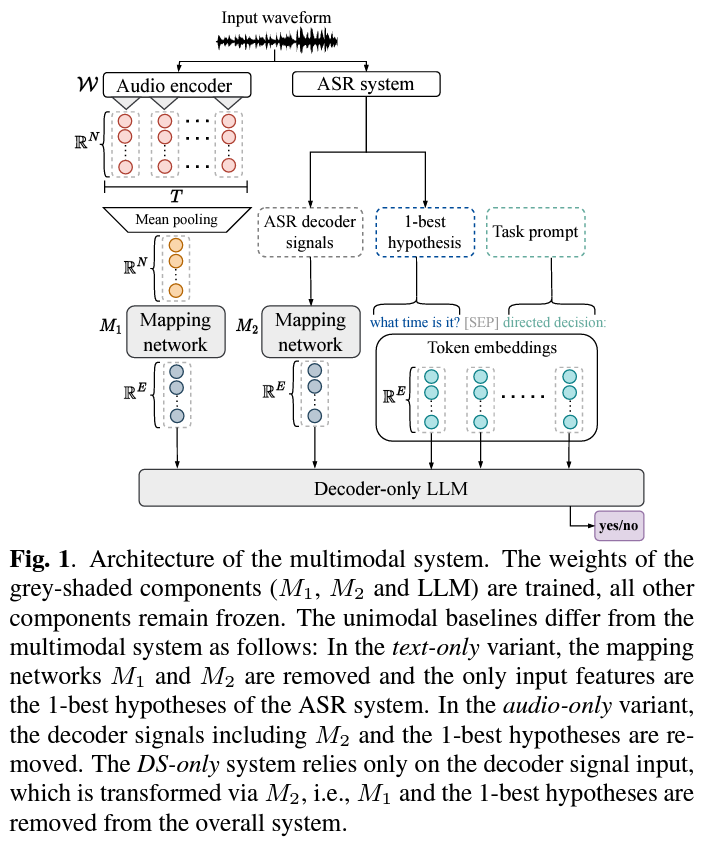
To achieve this feat, the researchers developed a methodology that involves training classifiers using acoustic information extracted from audio waveforms. By incorporating decoder outputs from ASR systems, including hypotheses and lexical features, into the LLM framework, Apple created a robust multimodal system capable of effectively categorizing and understanding speech directed at devices.
The results speak for themselves, with the multimodal system showcasing significant improvements over conventional models. Notably, it achieved impressive equal error rate (EER) reductions of up to 39% and 61% compared to text-only and audio-only models, respectively. Through the strategic enlargement of the LLM and the application of low-rank adaptation techniques, the research team further enhanced these EER reductions by up to 18% on their dataset.
Apple’s pioneering research not only sets a new benchmark in the field but also opens doors to more intuitive interactions with virtual assistants. By seamlessly integrating text, audio, and decoder signals from ASR systems, Apple’s approach propels technology closer to a future where devices comprehend and respond to user commands without the constraints of explicit trigger phrases.
Conclusion
Apple’s multimodal AI approach to speech detection represents a significant leap forward in the realm of device interaction. By harnessing the capabilities of LLMs and integrating diverse data sources, Apple has redefined the standards for speech recognition and device responsiveness. This research not only showcases the potential of advanced AI systems but also underscores Apple’s commitment to enhancing user experiences through innovative technological solutions.














{kind=link}