 Photo by
Photo by Hailing from the hustle and bustle of the city, this journalist is always on the lookout for intriguing stories that captivate the imagination. With a keen eye for detail, they uncover the hidden tales behind the AI wonders of our time.
The Quest for Efficient AI
In the realm of artificial intelligence, the pursuit of efficiency without compromising effectiveness is a constant challenge. Large Language Models (LLMs), with their expansive parameter spaces, have been at the forefront of this quest, demonstrating unparalleled capabilities in data processing, analysis, and complex problem-solving. However, the computational demands of leveraging these models to their full potential have often been a stumbling block, necessitating a search for innovative solutions.
 A visual metaphor for the distillation process of LLMs
A visual metaphor for the distillation process of LLMs
A Collaborative Breakthrough
A recent collaborative study between the University of Michigan and Apple has shed light on a promising approach to this challenge. The researchers focused on distillation, a process aimed at enhancing the model’s efficiency by simplifying its operations. The key insight of their work is the distinction between two phases of task execution: problem decomposition and problem-solving. They hypothesized that the initial phase of breaking down complex tasks into simpler subtasks could be distilled into smaller models more effectively than the latter.
Experimentation and Results
The team embarked on a series of experiments to distill the decomposition capability of LLMs into more manageable models. By isolating the decomposition task, they aimed for a targeted optimization of this phase. The results were compelling: the distilled models not only retained high performance across various tasks and datasets but also demanded significantly less computational power. This breakthrough suggests a path toward more cost-effective and efficient use of LLMs, enabling faster inference times without sacrificing quality.
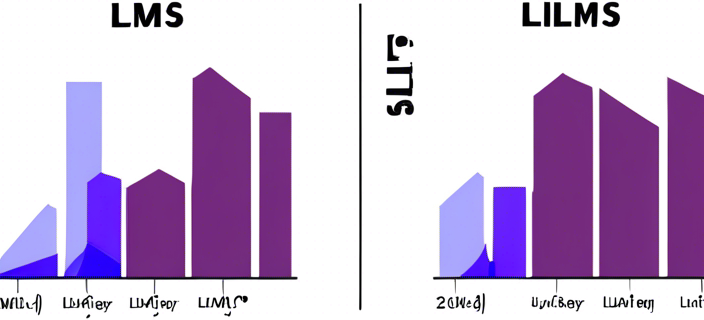 Performance metrics of original vs. distilled LLMs
Performance metrics of original vs. distilled LLMs
Implications and Future Directions
This research marks a significant step forward in the field of artificial intelligence. By successfully distilling the decomposition phase of LLMs, the researchers have opened up new possibilities for the efficient and effective use of these powerful tools. The implications of this approach are vast, promising not only cost savings and increased accessibility to LLM technology but also paving the way for further exploration into optimizing LLMs for a wide range of applications.
“This breakthrough research…marks a significant advancement in artificial intelligence.”
The findings from this collaboration between academia and industry highlight the potential for targeted distillation of LLM capabilities as a viable strategy for enhancing model efficiency. As the field of AI continues to evolve, the insights gained from this project will undoubtedly contribute to the ongoing dialogue on how best to leverage the immense potential of large language models in a sustainable and impactful manner.
In conclusion, the joint effort by the University of Michigan and Apple represents a leap forward in our quest to make AI more efficient and accessible. The success of their approach offers a glimpse into a future where the power of LLMs can be harnessed more sustainably, opening up new horizons for innovation across industries and research domains.












