
Can We Trust AI to Tell the Truth?
The digital era is struggling with the issue of factual accuracy across multiple spheres. Large Language Models (LLMs), in particular, struggle with facts. This isn’t primarily the fault of the LLMs themselves; if the data used to train an LLM is inaccurate, the output will be too.
 The issue of factual accuracy in LLMs
The issue of factual accuracy in LLMs
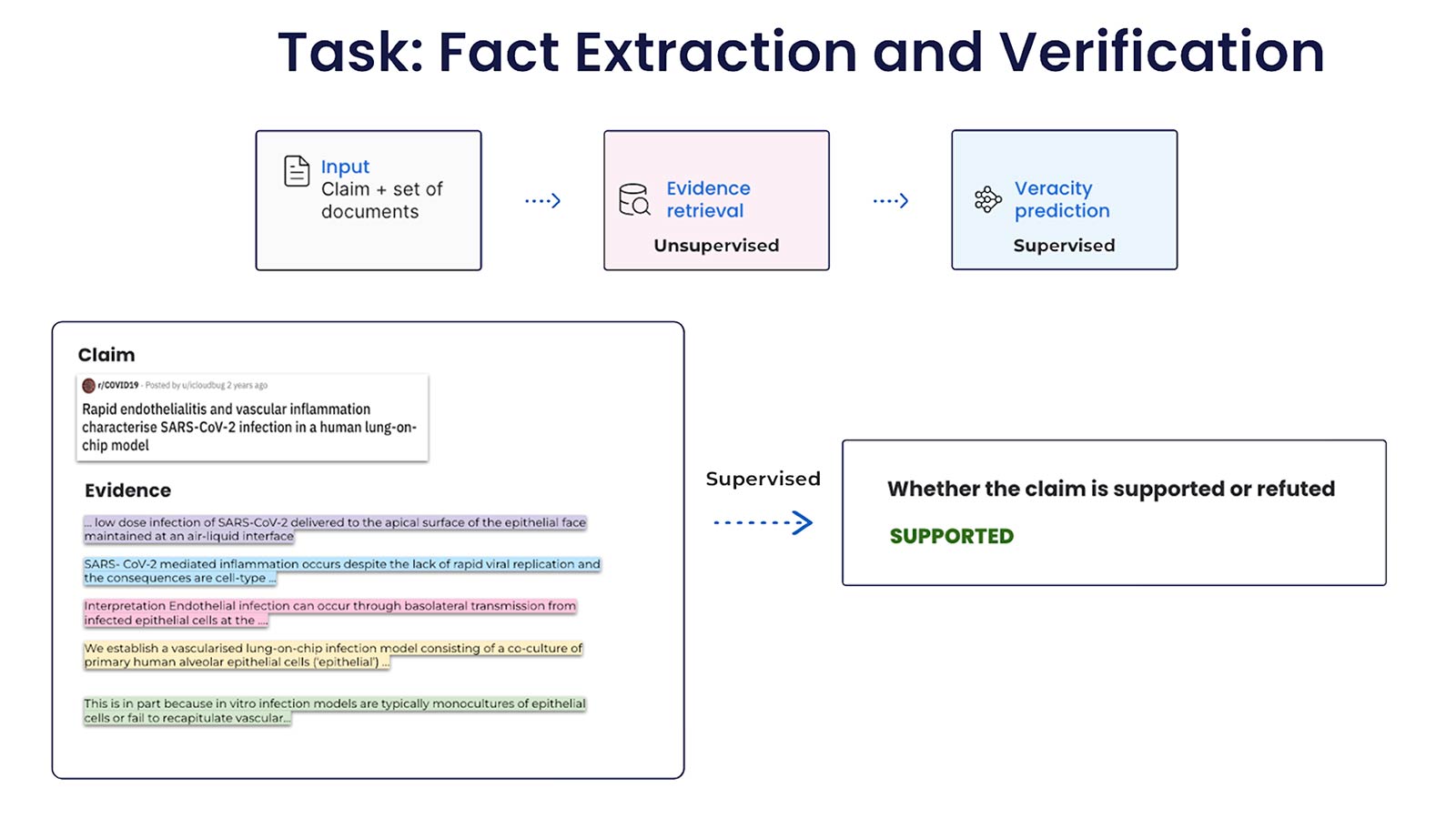
But what if we could teach LLMs to fact-check themselves? A team of researchers from IBM, MIT, Boston University, and Monash University in Indonesia has suggested techniques they believe could address the shortcomings in the way LLMs are trained. The team’s alternative is something called deductive closure training (DCT), whereby the LLM assesses the accuracy of its own output.
“The IBM research doesn’t seem to address the root cause of why LLMs are bad at facts, but it suggests there is a useful but unspectacular modification that might make them less bad at the things they’re currently bad at,” - Mark Stockley, co-presenter of The AI Fix podcast.
In unsupervised mode, the LLM is given “seed” statements which it uses to generate a cloud of statements inferred from them, some of which are true, others which aren’t. The LLM model then analyses the probability that each of these statements is true by plotting a graph of their consistency. When supervised by humans, the model can also be seeded with statements known to be true.
Deductive closure training in action
Meanwhile, a second team has suggested a way to refine this further using a technique called self-specialization, essentially a way of turning a generalist model into a specialist one by ingesting material from specific areas of knowledge.
“They could give the model a genetics dataset and ask the model to generate a report on the gene variants and mutations it contains,” - IBM.
This might sound rather like a way of implementing RAG. The difference is that these specialist models are only called upon, via an API, when they are needed, the researchers said.
So, can we trust AI to tell the truth? While the research doesn’t address the root cause of why LLMs are bad at facts, it suggests there is a useful but unspectacular modification that might make them less bad at the things they’re currently bad at. Perhaps with further development, we can have LLMs that are not only good at specific tasks but also uncomplicated fact- or truth-checking engines.
 The future of AI fact-checking
The future of AI fact-checking
Related Links:
Image Credits:
- Image 1: LLM fact-checking failures (_search_image)
- Image 2: Deductive closure training (_search_image)
- Image 3: AI fact-checking (_search_image)














{kind=link}