
The Future of Large Language Models: Beyond the Hype
The world of artificial intelligence is abuzz with the latest advancements in Large Language Models (LLMs). It’s like Fashion Week, where tech giants are unveiling their latest creations, leaving us wondering what’s next. Imagine a world where LLMs can handle 1 million+ context inputs, a far cry from the 512 tokens of yesteryear. The question on everyone’s mind is, where’s the limit?
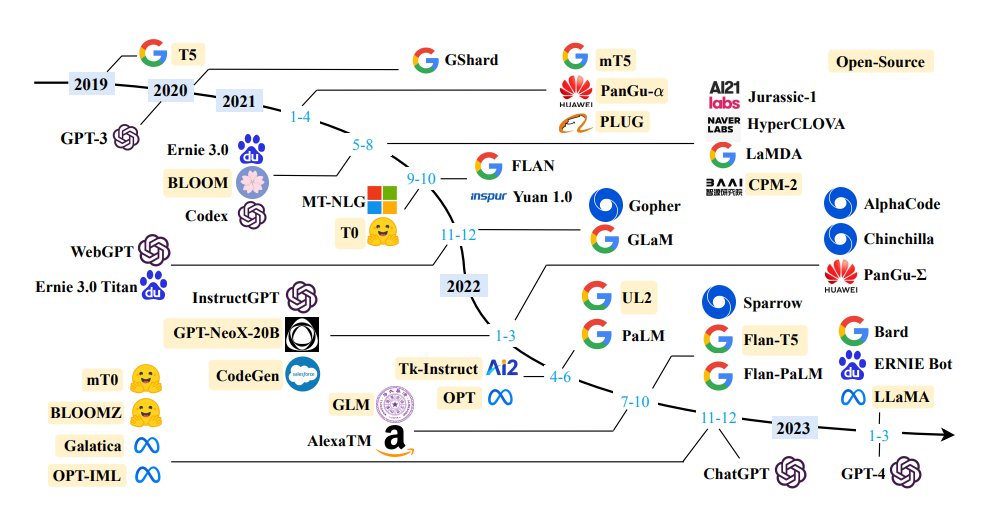 The ever-evolving landscape of LLMs
The ever-evolving landscape of LLMs
In Nigeria, a pioneering effort is underway to develop a multilingual LLM, capable of understanding and generating text in five indigenous languages. This groundbreaking project, led by Awarri, aims to create the largest dataset of native Nigerian languages, fueling the development of AI applications and bridging the technical knowledge gap in the region.
Awarri’s innovative approach to data collection
The implications of this technology are far-reaching, with the potential to accelerate AI adoption in Nigeria and beyond. As we hurtle towards an era of infinite context windows, the possibilities are endless. Will we see LLMs that can converse in multiple languages, understand nuances of local dialects, and drive economic growth in underserved regions?
The future of LLMs: where context knows no bounds
As we navigate this uncharted territory, one thing is certain – the future of LLMs is bright, and the possibilities are endless. Join us as we delve deeper into the world of artificial intelligence, where the boundaries of code and consciousness are constantly being pushed.
“A first for Nigeria, this launch is a critical step in the development of AI in Africa.” – Silas Adekunle, CEO of Awarri














{kind=link}